Topic perimeterx bypass: Discover proven techniques to bypass PerimeterX and achieve seamless web scraping. From using headless browsers and residential proxies to solving CAPTCHA challenges, learn how to effectively navigate PerimeterX's advanced security measures. This guide provides practical steps and tips for developers looking to bypass PerimeterX without getting detected.
Table of Content
- How to Bypass PerimeterX
- Introduction to PerimeterX Bypass
- 1. Understanding PerimeterX's Bot Defender
- 2. Passing PerimeterX's Backend Detection Techniques
- 3. Using High Quality Residential Proxies
- 4. Utilizing Headless Browsers
- 5. Implementing Browser Automation with Selenium
- 6. Using Puppeteer with Stealth Plugin
- 7. Scraping Google Cache
- 8. Solving PerimeterX JavaScript Challenges
- 9. Bypassing Captchas with CAPTCHA Solving Services
- 10. Mimicking Human Behavior
- 11. Traffic Routing Through Proxy Servers
- 12. Regular Maintenance and Optimization
- YOUTUBE:
How to Bypass PerimeterX
PerimeterX is a sophisticated bot detection and mitigation platform designed to protect websites from automated attacks. However, there are several methods to bypass its defenses. Below, we outline effective techniques for bypassing PerimeterX:
1. Using Headless Browsers
Headless browsers such as Puppeteer, Selenium, and Playwright can simulate real user interactions. These browsers run without a graphical user interface, allowing for automation while appearing genuine to detection systems.
- Realistic Traffic Patterns: Requests originate from an actual browser instance, making traffic characteristics appear human-like.
- Handles JavaScript: Full JavaScript support allows execution of browser-side code, defeating profiling scripts.
- Persistent Sessions: Cookies and sessions are maintained across IP rotations.
2. Using Residential Proxies
Residential proxies provide IP addresses assigned by ISPs to real individuals, making them harder to detect as bots.
- High-Quality IPs: Using residential proxies helps bypass IP-based fingerprinting.
- Rotating Proxies: Regularly changing IP addresses can prevent detection.
3. Solving CAPTCHAs
CAPTCHAs are used to verify human users. Automated CAPTCHA solving services can handle this step.
import requests
api_key = 'YOUR_API_KEY'
captcha_url = 'https://example.com/captcha.png'
response = requests.get(f'http://2captcha.com/in.php?key={api_key}&method=base64&body={captcha_url}')
captcha_id = response.text.split('|')[1]
while True:
response = requests.get(f'http://2captcha.com/res.php?key={api_key}&action=get&id={captcha_id}')
if response.text.startswith('OK|'):
captcha_solution = response.text.split('|')[1]
break
4. Scraping Google Cache
If a website allows indexing by search engines, retrieving its cached version can bypass PerimeterX entirely.
import requests
from bs4 import BeautifulSoup
url = 'https://example.com'
cache_url = f'http://webcache.googleusercontent.com/search?q=cache:{url}'
response = requests.get(cache_url)
soup = BeautifulSoup(response.text, 'html.parser')
cached_content = soup.find('div', {'id': 'main-content'}).text
print(cached_content)
5. Bypassing JavaScript Challenges
PerimeterX often uses JavaScript challenges to verify users. These can be solved using headless browsers or specialized libraries.
const PerimeterX = require('perimeterx-js-sdk');
const perimeterx = new PerimeterX({
appId: 'YOUR_APP_ID',
cookieKey: 'YOUR_COOKIE_KEY',
authToken: 'YOUR_AUTH_TOKEN'
});
perimeterx.challenge('https://example.com')
.then(page => {
console.log(page.content());
})
.catch(error => {
console.error(error);
});
6. Mimicking Human Behavior
Simulating realistic user interactions such as mouse movements, scrolling, and clicking can help evade behavioral analysis.
- Nonlinear Mouse Movements: Avoid straight-line movements to mimic human behavior.
- Variable Scrolling Speeds: Scroll at varying speeds to appear natural.
- Random Element Hovering: Hover over random elements before clicking.
Conclusion
Bypassing PerimeterX involves a combination of techniques including using headless browsers, residential proxies, solving CAPTCHAs, and mimicking human behavior. Implementing these methods carefully can help avoid detection.
READ MORE:
Introduction to PerimeterX Bypass
Bypassing PerimeterX involves understanding its sophisticated bot detection mechanisms and implementing effective strategies to overcome them. PerimeterX employs a combination of backend and client-side detection techniques, including IP reputation analysis, HTTP header inspection, and behavioral analysis. The following methods provide a detailed guide on how to bypass these protections step by step.
- Using High-Quality Residential Proxies: Residential proxies provide IP addresses assigned by ISPs, making them appear as legitimate users. This helps in bypassing IP-based detection techniques.
- Utilizing Headless Browsers: Tools like Puppeteer, Selenium, and Playwright can simulate human browsing behavior, executing JavaScript and managing cookies to avoid detection.
- Solving CAPTCHAs: Automated CAPTCHA solving services, such as 2captcha, can handle challenges presented by PerimeterX to verify human users.
- Scraping Google Cache: Accessing cached versions of websites via search engines like Google can bypass real-time detection and restrictions.
- Mimicking Human Behavior: Simulating realistic user interactions, such as random mouse movements, scrolling, and clicks, can help evade behavioral analysis.
- Implementing Browser Automation: Browser automation with tools like Puppeteer Stealth or Selenium Stealth can help mask automation indicators and prevent detection.
These techniques require careful implementation and continuous adaptation to effectively bypass PerimeterX without getting detected.
1. Understanding PerimeterX's Bot Defender
PerimeterX's Bot Defender is a sophisticated security solution designed to protect websites and applications from automated threats. It utilizes a combination of behavioral analysis, machine learning, and advanced fingerprinting techniques to identify and mitigate malicious bots in real-time. Understanding its key components and how it operates is crucial for any attempt to bypass it.
Key Components of PerimeterX's Bot Defender:
- Behavioral Analysis: This involves monitoring user interactions with the website to distinguish between human users and bots. Factors such as mouse movements, keystrokes, and page scrolling are analyzed to detect anomalies.
- Machine Learning: PerimeterX employs machine learning algorithms to continuously improve its detection capabilities. These algorithms are trained on vast amounts of data to identify patterns and behaviors associated with bots.
- Device Fingerprinting: This technique involves collecting detailed information about the user's device, such as browser type, operating system, screen resolution, and installed plugins. This data is used to create a unique fingerprint that helps in identifying bots.
- JavaScript Challenges: PerimeterX uses JavaScript challenges to gather additional data from the client-side. These challenges are designed to be easy for humans to solve but difficult for bots, helping to verify the legitimacy of the user.
- Backend Detection: In addition to client-side techniques, PerimeterX analyzes server-side traffic patterns and behaviors to identify suspicious activities. This dual approach ensures a comprehensive defense against bots.
How PerimeterX Bot Defender Works:
- Initial Request: When a user makes an initial request to a website protected by PerimeterX, a JavaScript snippet is injected into the webpage.
- Data Collection: The JavaScript snippet collects various data points about the user's device and behavior, sending this information back to the PerimeterX servers for analysis.
- Behavioral Analysis: The collected data is analyzed in real-time to determine if the user exhibits bot-like behavior. This includes evaluating interaction patterns and device characteristics.
- Machine Learning Evaluation: The data is further processed by machine learning algorithms that compare it against known patterns of bot and human activity.
- Challenge and Verification: If the analysis indicates potential bot activity, the user may be presented with additional challenges, such as CAPTCHAs or other verification methods.
- Response Decision: Based on the analysis and any additional challenge results, PerimeterX decides whether to allow the request, block it, or subject it to further scrutiny.
By understanding the mechanisms behind PerimeterX's Bot Defender, you can better appreciate the challenges involved in bypassing it and the sophistication of the technology protecting websites from automated threats.
2. Passing PerimeterX's Backend Detection Techniques
PerimeterX employs sophisticated backend detection techniques to identify and block automated bot traffic. To successfully bypass these measures, it is essential to understand and counteract the specific methods used by PerimeterX. Below are key backend detection techniques and strategies to pass them:
-
IP Quality:
PerimeterX calculates an IP address reputation score based on factors such as association with known bot networks, geographic location, ISP, and reputation history. To achieve a high IP address reputation score, it is recommended to use high-quality residential or mobile proxies instead of datacenter proxies or VPNs. This helps in mimicking real user traffic more effectively.
-
HTTP Browser Headers:
PerimeterX scrutinizes the HTTP headers sent with requests and compares them to a database of legitimate browser header patterns. Most HTTP clients send default headers that can be easily detected. Therefore, it is crucial to customize these headers to match those of a real browser. Utilize tools and APIs that generate realistic browser headers to avoid detection.
-
TLS & HTTP/2 Fingerprints:
PerimeterX uses TLS and HTTP/2 fingerprinting to validate the authenticity of a client. Each HTTP client generates unique fingerprints, which PerimeterX uses to verify the client's identity. To bypass this, you need to spoof these fingerprints, which requires capturing and analyzing packets from legitimate browsers. Using HTTP clients that allow low-level manipulation of these fingerprints, such as specific Golang or Node.js libraries, can help achieve this.
Implementing these strategies requires technical expertise and regular updates to stay ahead of PerimeterX's evolving detection mechanisms. Combining multiple techniques, such as using residential proxies and customizing HTTP headers, enhances the chances of bypassing PerimeterX's backend detection successfully.
3. Using High Quality Residential Proxies
Residential proxies are essential for bypassing PerimeterX's bot detection systems. These proxies route your web traffic through real residential IP addresses, making it difficult for PerimeterX to distinguish between legitimate users and automated bots. Here's how to use high-quality residential proxies effectively:
- Choose a Reliable Provider: Select a proxy provider known for its large pool of residential IPs and advanced features. Popular providers include Bright Data, Oxylabs, GeoSurf, and Smartproxy.
- Intelligent Proxy Rotation: Rotate proxies carefully to avoid detection. Change proxies on a per-URL or per-domain basis after a set number of requests, and use backoff strategies to disable IPs temporarily if they start getting blocked.
- Manage Scraper Concurrency: Limit the number of concurrent requests per proxy to blend with organic traffic levels. This avoids overloading any single IP, making your traffic appear more natural.
- Leverage Proxy Specialization: Use dedicated anti-bot residential IP pools that are designed to bypass fingerprinting and exhibit real human attributes. These pools often come with features like autoscaling ports and end-to-end scraping solutions.
Steps to Implement Residential Proxies:
- Sign Up for a Proxy Service: Register with a reputable proxy provider that offers residential IPs.
- Configure Proxy Settings: Set up your scraper or browser automation tool to use the proxies. This typically involves inputting the proxy server details into your network settings or script configuration.
- Rotate Proxies Strategically: Implement a rotation strategy to switch proxies periodically, ensuring that each IP address is used for a limited number of requests before switching to another.
- Monitor Performance: Regularly check the performance and health of your proxies. Replace any that become blocked or flagged to maintain seamless operations.
By following these steps and utilizing high-quality residential proxies, you can effectively bypass PerimeterX's detection mechanisms and carry out web scraping activities with minimal risk of being blocked.

4. Utilizing Headless Browsers
Headless browsers are essential tools for bypassing PerimeterX's detection mechanisms. They allow you to run browser automation scripts without a graphical user interface, making them faster and less resource-intensive. Here is a detailed guide on how to effectively use headless browsers to bypass PerimeterX.
Benefits of Using Headless Browsers
- Realistic Traffic Patterns: Requests originate from an actual browser instance, ensuring genuine traffic characteristics such as headers, device fingerprints, and timings.
- JavaScript Execution: Full support for JavaScript allows for the execution of browser-side code, defeating PerimeterX's JS profiling and bot detection scripts.
- Persistent Sessions: Cookies and site sessions are maintained properly across IP rotations, avoiding the appearance of multiple sessions from one user.
- CAPTCHA Handling: Integration with CAPTCHA solving services to defeat validation challenges.
- Human-like Interaction: Simulates mouse movements, scrolls, and clicks to avoid triggering PerimeterX's behavioral analysis models.
Steps to Implement Headless Browsers
- Set Up Puppeteer:
Install Puppeteer, a Node.js library which provides a high-level API to control Chrome or Chromium over the DevTools Protocol.
npm install puppeteerLaunch Puppeteer in headless mode:
const puppeteer = require('puppeteer'); (async () => { const browser = await puppeteer.launch({ headless: true }); const page = await browser.newPage(); await page.goto('https://example.com'); await page.screenshot({ path: 'example.png' }); await browser.close(); })(); - Use Puppeteer Extra Plugin Stealth:
This plugin makes headless Puppeteer less detectable. Install it with:
npm install puppeteer-extra puppeteer-extra-plugin-stealthIntegrate the plugin with Puppeteer:
const puppeteer = require('puppeteer-extra'); const StealthPlugin = require('puppeteer-extra-plugin-stealth'); puppeteer.use(StealthPlugin()); (async () => { const browser = await puppeteer.launch({ headless: true }); const page = await browser.newPage(); await page.goto('https://example.com'); await page.screenshot({ path: 'example.png' }); await browser.close(); })(); - Configure Browser Profiles:
Randomly change user agents and other browser properties to avoid detection:
const userAgents = [ 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36' ]; const randomIndex = Math.floor(Math.random() * userAgents.length); (async () => { const browser = await puppeteer.launch({ headless: true }); const page = await browser.newPage(); await page.setUserAgent(userAgents[randomIndex]); await page.goto('https://example.com'); await page.screenshot({ path: 'example.png' }); await browser.close(); })();
Best Practices
- Simulate Human Interaction: Use libraries like
puppeteer-extra-plugin-stealthto simulate realistic mouse movements and interactions. - Rotate Proxies: Utilize high-quality residential proxies to minimize the risk of IP blocks.
- Monitor and Adjust: Regularly monitor the success rates of your requests and adjust your strategies accordingly to stay ahead of PerimeterX's detection updates.
5. Implementing Browser Automation with Selenium
Selenium is a powerful tool for automating web browsers, which can be instrumental in bypassing PerimeterX's detection mechanisms. Here is a detailed, step-by-step guide on how to implement browser automation with Selenium to bypass PerimeterX:
- Setting Up Selenium:
- Install Selenium: You can install Selenium using pip:
pip install selenium - Download WebDriver: Depending on the browser you want to automate (e.g., Chrome, Firefox), download the corresponding WebDriver.
- Install Selenium: You can install Selenium using pip:
- Launching a Browser Instance:
- Import necessary libraries and initialize the WebDriver:
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys # For Chrome driver = webdriver.Chrome(executable_path='/path/to/chromedriver') # For Firefox # driver = webdriver.Firefox(executable_path='/path/to/geckodriver') - Set options to make the browser appear more human-like. For example, using ChromeOptions to avoid detection:
from selenium.webdriver.chrome.options import Options options = Options() options.add_argument('--disable-blink-features=AutomationControlled') driver = webdriver.Chrome(options=options)
- Import necessary libraries and initialize the WebDriver:
- Interacting with the Web Page:
- Navigate to the target website:
driver.get('https://targetwebsite.com') - Perform actions such as clicking buttons, filling forms, and scrolling to simulate human behavior:
search_box = driver.find_element(By.NAME, 'q') search_box.send_keys('Selenium') search_box.send_keys(Keys.RETURN) - Implement random delays and varied interaction patterns to avoid detection:
import time import random time.sleep(random.uniform(1, 3))
- Navigate to the target website:
- Handling JavaScript Challenges and CAPTCHAs:
- Use browser automation tools to execute JavaScript and handle challenges:
driver.execute_script("return document.title") - Integrate CAPTCHA solving services if necessary, but avoid triggering CAPTCHAs by mimicking natural browsing patterns.
- Use browser automation tools to execute JavaScript and handle challenges:
- Optimizing for Scalability:
- Use headless mode to run browsers without a graphical interface, saving resources:
options.headless = True driver = webdriver.Chrome(options=options) - Rotate IP addresses using high-quality residential proxies to distribute traffic and reduce the risk of detection.
- Use headless mode to run browsers without a graphical interface, saving resources:
By following these steps, you can effectively use Selenium to bypass PerimeterX's detection techniques. Always ensure your automation scripts are up-to-date with the latest browser and WebDriver versions to avoid compatibility issues.
6. Using Puppeteer with Stealth Plugin
The Puppeteer Stealth plugin helps in masking the properties of headless browsers to avoid detection mechanisms like PerimeterX. Follow these steps to integrate Puppeteer with the Stealth plugin:
- Install Puppeteer Extra and Stealth Plugin
First, install the necessary packages by running the following command:
npm install puppeteer-extra puppeteer-extra-plugin-stealth - Set Up Puppeteer Extra and Register the Stealth Plugin
Replace the default Puppeteer import with Puppeteer Extra and register the Stealth plugin:
import puppeteer from 'puppeteer-extra'; import StealthPlugin from 'puppeteer-extra-plugin-stealth'; puppeteer.use(StealthPlugin());For CommonJS users, use:
const puppeteer = require('puppeteer-extra'); const StealthPlugin = require('puppeteer-extra-plugin-stealth'); puppeteer.use(StealthPlugin());You can also enable specific evasion techniques:
puppeteer.use(StealthPlugin({ enabledEvasions: new Set(['chrome.app', 'chrome.csi', 'defaultArgs', 'navigator.plugins']) })); - Integrate and Execute
Combine everything into your Puppeteer script and run it:
import puppeteer from 'puppeteer-extra'; import StealthPlugin from 'puppeteer-extra-plugin-stealth'; (async () => { puppeteer.use(StealthPlugin()); const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto('https://example.com'); // Your scraping logic here await browser.close(); })();
By following these steps, you can effectively use Puppeteer with the Stealth plugin to minimize the risk of detection by anti-bot mechanisms like PerimeterX.
7. Scraping Google Cache
Scraping Google Cache can be an effective method to bypass PerimeterX's anti-bot measures. This approach leverages Google's cached versions of web pages, which are often not protected by the same bot mitigation systems. Here's a step-by-step guide on how to implement this technique:
-
Understanding Google Cache:
Google and other search engines periodically crawl and store cached copies of web pages. Accessing these cached versions allows you to retrieve the content without directly interacting with the target site, thus avoiding PerimeterX's defenses.
-
Forming the Cache URL:
To access a cached page, use the following URL format:
http://webcache.googleusercontent.com/search?q=cache:[URL]Replace
[URL]with the URL of the page you want to scrape. For example:http://webcache.googleusercontent.com/search?q=cache:https://www.example.com -
Scraping the Cached Page:
Use your preferred scraping tool or script to fetch and parse the content from the cached URL. Here's an example using Python and the
requestslibrary:import requests url = "http://webcache.googleusercontent.com/search?q=cache:https://www.example.com" response = requests.get(url) print(response.text) -
Handling Limitations:
While scraping Google Cache can bypass many anti-bot systems, it has limitations:
- Data may be outdated, as it depends on the last crawl by Google.
- Not all pages are cached, especially those that are dynamically generated or restricted by robots.txt.
- Limited scalability, suitable for occasional scraping but not for large-scale operations.
Despite these limitations, scraping Google Cache is a low-effort and effective method for bypassing bot mitigation when real-time data is not critical.
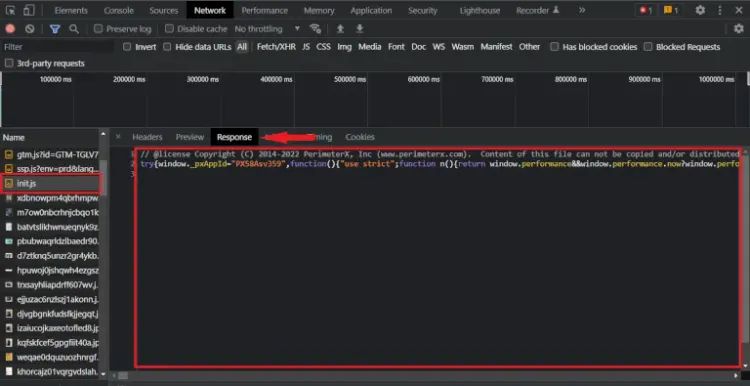
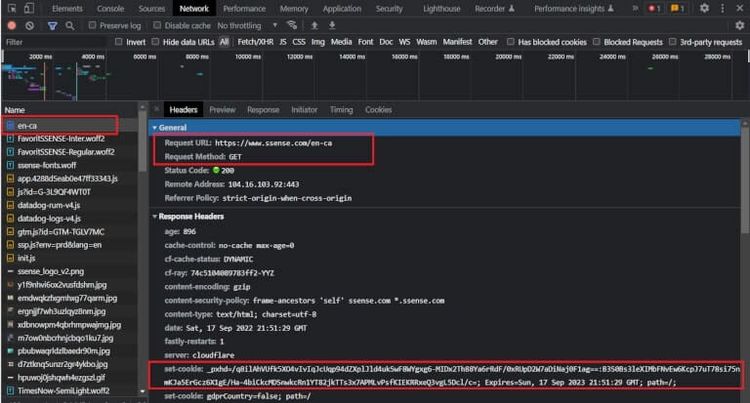
8. Solving PerimeterX JavaScript Challenges
PerimeterX employs sophisticated JavaScript challenges to identify and block automated bots. Solving these challenges is critical for bypassing their detection systems. Here's a detailed step-by-step guide on how to tackle these JavaScript challenges effectively:
-
Understanding the JavaScript Challenge:
PerimeterX injects JavaScript into web pages to create challenges that test for bot behavior. These scripts analyze interactions, such as mouse movements, clicks, and keystroke dynamics, to distinguish between humans and bots.
-
Using Headless Browsers:
Headless browsers like Puppeteer, Selenium, and Playwright can be used to execute these JavaScript challenges. These tools automate a real browser without displaying a user interface, making it easier to mimic human interactions.
const puppeteer = require('puppeteer'); (async () => { const browser = await puppeteer.launch({ headless: true }); const page = await browser.newPage(); await page.goto('https://example.com'); // Add necessary interactions to solve the challenge const content = await page.content(); console.log(content); await browser.close(); })(); -
Using Stealth Plugins:
Puppeteer Stealth Plugin and similar tools for Selenium (like undetected-chromedriver) help bypass JavaScript fingerprinting by modifying browser behavior to appear more like a regular browser. This includes patching TLS, HTTP headers, and other fingerprinting techniques.
const puppeteer = require('puppeteer-extra'); const StealthPlugin = require('puppeteer-extra-plugin-stealth'); puppeteer.use(StealthPlugin()); (async () => { const browser = await puppeteer.launch({ headless: true }); const page = await browser.newPage(); await page.goto('https://example.com'); const content = await page.content(); console.log(content); await browser.close(); })(); -
Reverse Engineering JavaScript:
In some cases, you might need to reverse engineer the JavaScript challenges. This involves analyzing the challenge scripts to understand how they generate and validate the tokens required to bypass the challenge. Tools like browser developer consoles and JavaScript debuggers are essential for this process.
-
Executing Challenges Manually:
When automation is insufficient, you can manually interact with the JavaScript challenge in a headless browser environment. This involves simulating real user behavior through scripted interactions such as mouse movements and key presses.
Successfully solving PerimeterX JavaScript challenges requires a combination of browser automation, stealth techniques, and sometimes manual intervention. By understanding and executing these steps, you can effectively bypass PerimeterX's detection mechanisms.
9. Bypassing Captchas with CAPTCHA Solving Services
CAPTCHAs are designed to differentiate between human users and bots, making them a common hurdle for automated tasks. Here are several steps and methods for bypassing CAPTCHAs using CAPTCHA solving services:
-
1. Understanding CAPTCHA Types
CAPTCHAs come in various forms such as text-based challenges, image-based challenges, audio CAPTCHAs, and more. Each type requires a different approach for solving.
-
2. Selecting a CAPTCHA Solving Service
There are numerous CAPTCHA solving services available. Popular ones include:
- 2Captcha: Supports various CAPTCHA types including reCAPTCHA, hCaptcha, and image CAPTCHAs.
- Anti-Captcha: Offers solutions for complex CAPTCHA challenges and provides API integration.
- NopeCHA: Provides browser extensions and API support for automated CAPTCHA solving.
-
3. Integrating the CAPTCHA Solving Service
Integration typically involves setting up API calls within your automation script. Here is a basic example using Python:
import requests API_KEY = 'your_api_key' captcha_image_url = 'http://example.com/captcha.jpg' response = requests.post( 'http://2captcha.com/in.php', data={'key': API_KEY, 'method': 'base64', 'body': captcha_image_url} ) if response.status_code == 200: captcha_id = response.text.split('|')[1] result = requests.get(f'http://2captcha.com/res.php?key={API_KEY}&action=get&id={captcha_id}') if result.text == 'OK|': captcha_solution = result.text.split('|')[1] print(f'Captcha Solved: {captcha_solution}') -
4. Handling CAPTCHA Solving Responses
After receiving the solved CAPTCHA, the response needs to be correctly submitted back to the target website. Ensure your script correctly handles the submission of the solved CAPTCHA token.
-
5. Automating CAPTCHA Solving
Automate the process using libraries and tools that support CAPTCHA solving. For instance, Selenium combined with CAPTCHA solving services can be powerful:
from selenium import webdriver from selenium.webdriver.common.by import By import requests driver = webdriver.Chrome() driver.get('http://example.com') captcha_image = driver.find_element(By.ID, 'captcha_image').get_attribute('src') response = requests.post( 'http://2captcha.com/in.php', data={'key': API_KEY, 'method': 'base64', 'body': captcha_image} ) if response.status_code == 200: captcha_id = response.text.split('|')[1] result = requests.get(f'http://2captcha.com/res.php?key={API_KEY}&action=get&id={captcha_id}') if result.text == 'OK|': captcha_solution = result.text.split('|')[1] driver.find_element(By.ID, 'captcha_input').send_keys(captcha_solution) driver.find_element(By.ID, 'submit_button').click()
10. Mimicking Human Behavior
Mimicking human behavior is a crucial strategy for bypassing PerimeterX's detection mechanisms. By simulating human-like interactions with websites, bots can avoid triggering anti-bot systems. Here are detailed steps and techniques for effectively mimicking human behavior:
- Randomizing Delays:
Add random delays between actions to simulate human browsing patterns. For example, introduce pauses between page loads, clicks, and form submissions.
- Varying User Agents and Browser Profiles:
Change user agent strings and browser profiles regularly to prevent detection. Use a variety of browsers and operating systems to appear more human-like.
- Simulating Mouse Movements and Clicks:
Reproduce realistic mouse movements, clicks, and scrolls. This can involve moving the mouse cursor in a human-like manner, clicking buttons, and scrolling through pages.
- Interacting with Page Elements:
Engage with different elements on the page, such as hovering over links, opening dropdown menus, and interacting with form fields. This helps in mimicking genuine user behavior.
- Managing Request Rates and Intervals:
Control the rate at which requests are sent to avoid overwhelming the server. Implement random intervals and exponential backoff strategies to manage request frequency.
- Handling JavaScript Challenges:
Address JavaScript challenges by ensuring your bot can execute JavaScript similar to a human user. This may involve handling dynamic content and solving JavaScript-based puzzles.
By incorporating these techniques, your scraping activities can appear more natural and reduce the chances of detection by PerimeterX. Always aim to mimic the diverse and unpredictable nature of human interactions to stay under the radar.
11. Traffic Routing Through Proxy Servers
Routing traffic through proxy servers is an effective method to bypass PerimeterX detection mechanisms. This approach leverages the anonymity and distribution provided by proxies to simulate genuine user behavior. Here is a detailed guide on how to use proxy servers for this purpose:
-
Select a Reliable Proxy Provider:
Choose a proxy provider that offers high-quality residential proxies. Residential proxies are preferred because they are associated with real ISPs and are less likely to be blacklisted by PerimeterX.
-
Setup Proxy Rotation:
To avoid detection, it is crucial to rotate proxies periodically. Proxy rotation can be achieved using proxy rotation services or scripts that switch proxies after a set number of requests or a specific time interval.
-
Configure Proxy Settings:
In your scraping or automation tool, configure the proxy settings to route traffic through the selected proxies. For example, in Selenium, you can use the following code:
from selenium import webdriver from selenium.webdriver.common.proxy import Proxy, ProxyType proxy = Proxy() proxy.proxy_type = ProxyType.MANUAL proxy.http_proxy = "http://proxy_address:port" proxy.socks_proxy = "http://proxy_address:port" proxy.ssl_proxy = "http://proxy_address:port" capabilities = webdriver.DesiredCapabilities.CHROME proxy.add_to_capabilities(capabilities) driver = webdriver.Chrome(desired_capabilities=capabilities) driver.get("http://target_website.com") -
Distribute Requests Evenly:
Ensure that requests are evenly distributed across multiple proxies to avoid overwhelming any single proxy, which could lead to detection. Implement logic to track and balance request distribution.
-
Monitor Proxy Performance:
Regularly monitor the performance and health of your proxies. Replace any proxies that become slow or get blocked to maintain smooth operation.
By carefully managing proxy selection, rotation, and distribution, you can effectively route traffic through proxy servers and minimize the chances of detection by PerimeterX.

12. Regular Maintenance and Optimization
Regular maintenance and optimization are crucial for ensuring the effectiveness and longevity of your PerimeterX bypass techniques. Here are detailed steps to help you maintain and optimize your setup:
1. Monitor IP Reputation
Consistently monitor the reputation of your proxy IPs. Using residential or high-quality datacenter proxies is essential. You can use services like IPQualityScore to check IP reputations regularly.
2. Update User-Agent Strings
Regularly update the user-agent strings to mimic the latest browser versions. This helps in avoiding detection by PerimeterX's bot defender. Maintain a list of current user-agents and rotate them frequently.
3. Rotate Proxies
Use a rotating proxy service to ensure that your IP addresses change frequently, reducing the chances of detection. Ensure the proxies are of high quality and have good reputational scores.
4. Use Headless Browsers
Employ headless browsers like Puppeteer, Selenium, or Playwright. Ensure they are configured to mimic real user interactions. For added stealth, use libraries like selenium-stealth to modify browser characteristics.
5. Regularly Test and Update Scripts
PerimeterX frequently updates its detection methods. Regularly test your scripts against PerimeterX-protected sites and update them as needed to bypass new detection techniques.
6. Implement CAPTCHA Solving Services
Integrate CAPTCHA solving services like 2Captcha or Anti-Captcha to handle CAPTCHA challenges. Regularly test the effectiveness of these services and update API keys as necessary.
7. Scrape Google Cache
If applicable, scrape content from Google Cache to bypass PerimeterX altogether. This method can be useful for retrieving cached versions of pages without interacting directly with PerimeterX-protected sites.
8. Analyze and Mimic Traffic Patterns
Analyze traffic patterns of real users and mimic these patterns in your automation scripts. This includes randomizing request intervals, mimicking mouse movements, and simulating human interactions.
9. Keep Up with PerimeterX Updates
Stay informed about the latest updates and improvements in PerimeterX's detection methods. Participate in relevant forums, read industry blogs, and stay connected with the developer community to keep your knowledge current.
10. Regular Audits and Performance Checks
Conduct regular audits and performance checks on your bypass setup. Identify any areas of inefficiency and optimize your approach accordingly. This ensures that your system remains robust and effective over time.
Tại sao công ty an ninh mạng PerimeterX sử dụng Google Cloud
READ MORE:
Tìm hiểu cách bỏ qua phát hiện bằng Python Selenium với các plugin, cài đặt và proxy. Hướng dẫn chi tiết giúp bạn vượt qua các rào cản bảo mật.
Hướng dẫn Python Selenium #6 - Bỏ qua Phát hiện bằng Plugin, Cài đặt & Proxy